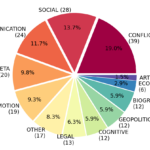
About
Tint (The Italian NLP Tool) is a Java-based pipeline for Natural Language Processing (NLP) in Italian. It is very fast and accurate, and implements most of the common linguistic tools, such as part-of-speech tagging and dependency parsing. The tool is based on Stanford CoreNLP, and can be used as a stand-alone tool, included as a Java library or as a REST API service. Tint also includes wrappers (for third-party tools) that use the CoreNLP paradigm and therefore can be applied to languages different than Italian.
Tint is completely free, open source, and its source code is released under the GNU General Public License (GPL) version 3.
Features
- Fast and accurate native basic NLP tasks (tokenization, sentence splitting, morphological analysis, lemmatization)
- Modules for part-of-speech tagging, dependency parsing and named entity recognition use state-of-the art technologies
- It includes wrappers for entity linking, time expression identification, keywords extraction, hyphenation, geocoding.
- Extensible interface, through Stanford CoreNLP library
- REST API service included, built on top of Grizzly
Publications
Please cite one of the following papers, if you use Tint in a scientific publication.
By Alessio Palmero Aprosio and Giovanni Moretti.
[tex]
@ARTICLE{2016arXiv160906204P,
author = {{Palmero Aprosio}, A. and {Moretti}, G.},
title = {Italy goes to Stanford: a collection of CoreNLP modules for Italian},
journal = {ArXiv e-prints},
eprint = {1609.06204},
keywords = {Computer Science – Computation and Language},
year = 2016,
adsurl = {http://adsabs.harvard.edu/abs/2016arXiv160906204P},
adsnote = {Provided by the SAO/NASA Astrophysics Data System}
}
[/tex]
By Alessio Palmero Aprosio and Giovanni Moretti.
[tex]
@ARTICLE{2018tint2,
author = {{Palmero Aprosio}, A. and {Moretti}, G.},
title = {Tint 2.0: an All-inclusive Suite for NLP in Italian},
keywords = {Computer Science – Computation and Language},
booktitle={Proceedings of the Fifth Italian Conference on Computational Linguistics CLiC-it},
volume={10},
pages={12},
year={2018}
}
[/tex]